4.2 Globales Modell



4.2 Globales Modell |
|
Beim globalen Modell findet keine Unterteilung der Population statt, die Population wird als ,,unstrukturierte Menge betrachtet" ([Swm96], S.68). Statt dessen wird die dem Evolutionären Algorithmus innewohnende Parallelität, die durch das Arbeiten mit einer Population vorhanden ist, ausgenutzt. Alle Individuen der Population werden zur Fitneßbestimmung verwendet und die Selektion der Individuen zur Reproduktion findet global statt. Individuen aus beliebigen Bereichen der Population können zusammen zur Bildung von Nachkommen ausgewählt werden. Das globale Modell entspricht dem klassischen Evolutionären Algorithmus.
Die Berechnungen, für welche die gesamte Population benötigt wird - Selektion und Fitneßzuweisung - werden von einer Zentrale ausgeführt. Die restlichen Berechnungen, die jeweils nur ein oder zwei (mehrere) Individuen gleichzeitig verwenden, werden jeweils an einen der vielen gleichartigen Arbeiter verschickt, die jeder für sich und parallel zueinander die Rekombination, Mutation und Zielfunktionsberechnung durchführen (bekannt als synchrone Master-Slave-Struktur, siehe Abbildung 4-2). Da diese Berechnungen parallel von mehreren Rechnern ausgeführt werden, läßt sich eine fast lineare Beschleunigung der Gesamtberechnung erzielen.
Für die meisten realen Probleme ist die Zielfunktionsberechnung der mit Abstand aufwendigste Teil der Berechnungen. In diesem Falle können nur die Zielfunktionsberechnungen auf die Arbeiter verteilt werden, der Evolutionäre Algorithmus an sich wird komplett von der Zentrale ausgeführt. Zusätzlicher Vorteil ist, daß statt zweier Individuen nur ein Individuum an den Arbeiter übertragen werden muß.
Falls dagegen der Aufwand zur Zielfunktionsberechnung im Vergleich zum Evolutionären Algorithmus gering ist, kann es zu Engpässen an der Zentrale kommen und das synchrone globale Modell wäre in dieser einfachen Struktur ineffektiv.
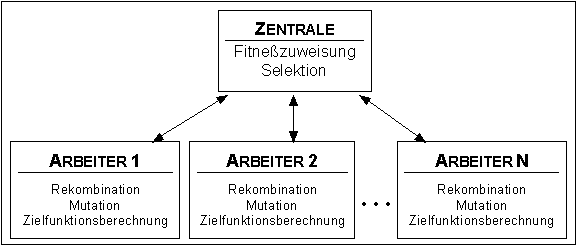
Abbildung 4-2: Populationsmodell: globales Modell (Master-Slave-Struktur)
Die Effizienz der Aufteilung der Berechnungen zwischen Zentrale und Arbeiter hängt entscheidend vom Aufwand der beiden Gruppen von Berechnungen ab. Ein Abgehen von der synchronen Arbeitsweise hin zu einem semi-synchronen oder asynchronen Algorithmus kann einige der Probleme verringern oder lösen [Gol89].
Ein Ansatz ist die Verwendung eines steady-state Algorithmus (siehe S.). Bei diesem werden jeweils ein oder zwei Individuen ausgewählt, die dann an einen Arbeiter geschickt werden, wo Rekombination, Mutation und Zielfunktionsberechnung durchgeführt werden. Sobald der Arbeiter fertig ist, werden die neuen Individuen an die Zentrale übergeben und nachfolgend erhält der Arbeiter neue Individuen. Bei diesem Algorithmus muß nicht auf die Beendigung der Berechnungen der anderen Arbeiter gewartet werden, jeder Arbeiter wird nach Ende der Aufgabe gleich mit einer neuen Berechnung beauftragt, wodurch die Arbeiter selbst immer ausgelastet sind. Voraussetzung ist natürlich, daß die Zentrale in der Lage ist, die Fitneßberechnung, Selektion und das Wiedereinfügen der Individuen in die Population schnell genug auszuführen. Aber auch bei diesem nur teilweise synchronen Algorithmus hängen alle Arbeiter von einer Zentrale ab.
Diesem Problem der Abhängigkeit von einer Zentrale (und damit einer eingeschränkten Robustheit) ist nur mittels eines asynchronen Ansatzes beizukommen. Dabei arbeiten mehrere Prozessoren parallel zueinander, wobei jeder einen kompletten Evolutionären Algorithmus ausführt. Ein Austausch zwischen diesen Prozessen findet entweder von Zeit zu Zeit in einer bestimmten Struktur statt (ähnlich wie nachfolgend bei der Migration beschrieben) oder alle Prozesse greifen gemeinsam auf einen Speicherbereich zu, über den diese Prozesse dann miteinander verbunden sind. Selbst wenn hier einige der Prozessoren ausfallen, läuft die gesamte Optimierung weiter.
Robertson [Rob87] berichtet von einer vollständigen Implementierung des globalen Modells, für die eine Connection Machine CM-1 mit 65536 Prozessoren eingesetzt wurde. Im Gegensatz zu anderen Implementierungen des globalen Modells wurde in [Rob87] auch die Selektion parallel ausgeführt. Weitere Implementierungen des globalen Modells wurden unter anderem in [FH91], [HM94] und [Swm96] berichtet.
Das globale Modell ist ein einfacher Weg, sehr lange Rechenzeiten einer Optimierung auf ein erträgliches Maß zu reduzieren. Außerdem läßt sich die Verteilung der Zielfunktionsberechnungen auf mehrere Rechner auch bei allen anderen Unterteilungen der Population anwenden.

Diese Dokument ist Teil der Dissertation von Hartmut Pohlheim
"Entwicklung und systemtechnische Anwendung Evolutionärer Algorithmen".
This document is part of the .
The is not free.
© Hartmut Pohlheim, All Rights Reserved,
(hartmut@pohlheim.com).